

Quantitative Cyber Risk Analysis with Open Source LLMs: Who Wins?
See Which AI Models Excel in Cybersecurity Risk Quantification


Open Source Large Language Models (LLMs) have become critical tools for organizations leveraging artificial intelligence in various domains, including cybersecurity risk analysis. The FAIR (Factor Analysis of Information Risk) framework offers a structured and quantitative approach to analyzing risk, especially relevant in the context of ransomware cyber attacks. This essay explores how different open-source LLMs perform in generating actionable insights for conducting a quantitative risk analysis of ransomware risks using the FAIR framework.
Why a quantitative risk analysis for ransomware using the FAIR framework?
I’m glad you asked…
Using a quantitative risk analysis approach is a great mix of creating (feasible) text and provide meaningful, calculations in one prompt. For sure, there might be more sophisticated testing prompts, it’s a great start to get a generic overview about how well a LLM is doing the job. The same approach is used for the cyber risk selection. Ransomware is omnipresent and applies to all organizations and individuals.
The key facts for the hardware are the following:
CPU: Intel i5 10400F
GPU: RTX 4070 Ti Super (16 GB VRAM)
RAM: 32 GB
Due to the sizing of the hardware, the candidate scope ranges from 8B - 32B parameters. Larger models are not capable to run reliably on this hardware setup.
The test candidates for LLMs include:
Mistral (7B; Q8)
Mistral-Nemo-Instruct 2407 (13B; Q6_K)
Llama 3.1 (8B; Q5_K_M)
Llama 3 (16B; Q5_K_M)
Qwen 2.5 (14B and 32B)
Teuken (7B; F16)
Gemma-2 (9B; Q8 and 27B; Q4_K_M)
Since this use case relies on advanced information in the cybersecurity and risk analysis sphere, the test setup was enhanced with a local RAG setup where the LLM got access to further information related to these domains.
The FAIR Framework and Ransomware Risk Analysis
The FAIR framework comprises key components: loss event frequency, loss magnitude, primary and secondary loss categories, and control effectiveness. This framework aids organizations in answering questions such as the probability of a ransomware event occurring, potential financial impacts, and control improvement strategies. An exemplary prompt to test the LLMs could be:
The prompt that has been used is the following:
create a full quantitative risk analysis using FAIR for a ransomware cyber attack.
Yes, it is as simple as that.
To learn more about FAIR and the benefits of leveraging quantitative risk analysis, you might want to look into this article:
Cyber Risk Quantification: Measuring The Unseen Threat

We are in the midst of an invisible war. We have been for a long time actually — but we don’t really grasp it.
Performance Analysis
Mistral Models
The Mistral (7B) model is characterized by its ability to deliver concise and efficient responses, making it suitable for simpler risk modeling scenarios. However, its limited parameter count constrains its capability to handle detailed complex calculations or provide nuanced recommendations.

The Mistral-Nemo-Instruct 2407 (13B) improves on its predecessor with enhanced contextual understanding and quantitative reasoning. This makes it more suitable for moderately complex tasks. Despite this, it sometimes falls short in elaborating scenarios or offering robust control strategy recommendations.

Llama Models
The Llama 3.1 (8B) model performs well for smaller-scale tasks, excelling at breaking down frameworks like FAIR into actionable steps. However, its capacity to synthesize detailed quantitative data is limited when working with larger datasets.
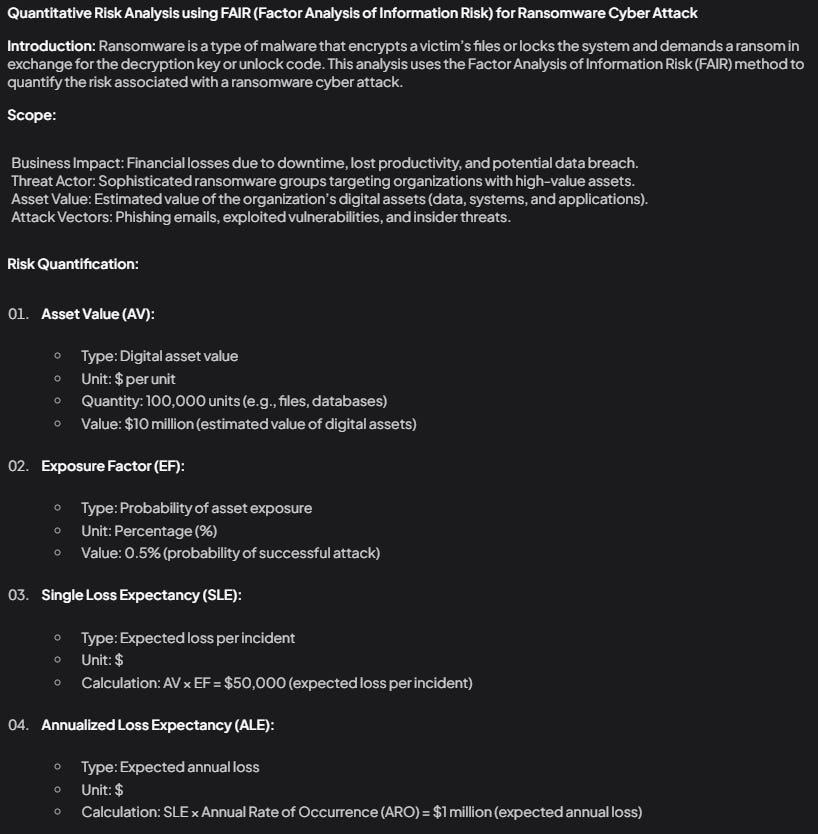
The Llama 3 (16B) offers a more comprehensive analysis, providing clear, step-by-step recommendations and maintaining a balance across tasks of varying complexity. Its primary drawback lies in a tendency toward verbosity, which does not always contribute to the substance of its outputs.

Qwen Models
The Qwen 2.5 (14B) strikes a balance between practical insights and precision, delivering reliable results for moderately detailed scenarios. Yet, its rigor does not match that of higher-parameter models, particularly in tasks requiring extensive quantitative detail.

In contrast, the Qwen 2.5 (32B) excels in accuracy and comprehensive output generation, making it highly effective for large, intricate scenarios. Its computational intensity, however, can hinder its practicality in resource-constrained environments.

Teuken
The Teuken (7B) model emphasizes speed and adherence to principles such as FAIR. It provides satisfactory results for simpler tasks but often oversimplifies complex elements, resulting in limited depth and precision.

Gemma Models
The Gemma-2 (9B) model is well-suited for mid-tier complexity tasks, balancing clarity and depth effectively. However, it occasionally struggles with numerical precision, leading to inconsistencies in outputs for certain calculations.
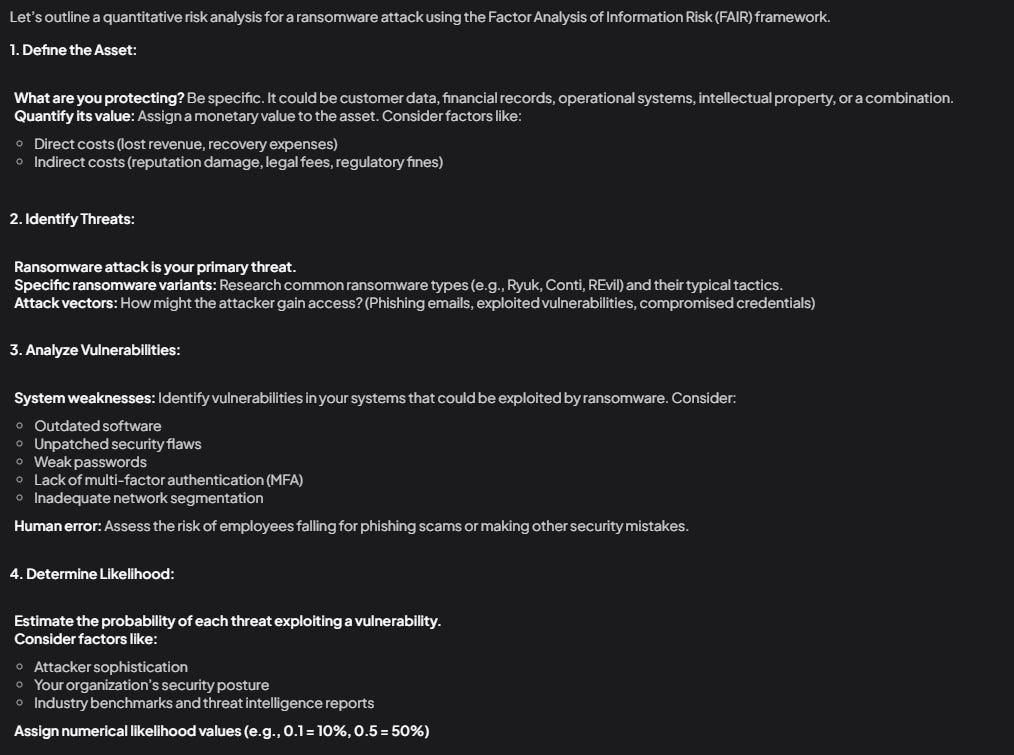
The Gemma-2 (27B) stands out for its detailed and accurate results, making it a strong choice for complex quantitative analyses. Its primary limitations are computational demands and relatively slower response times, which may affect time-sensitive applications:
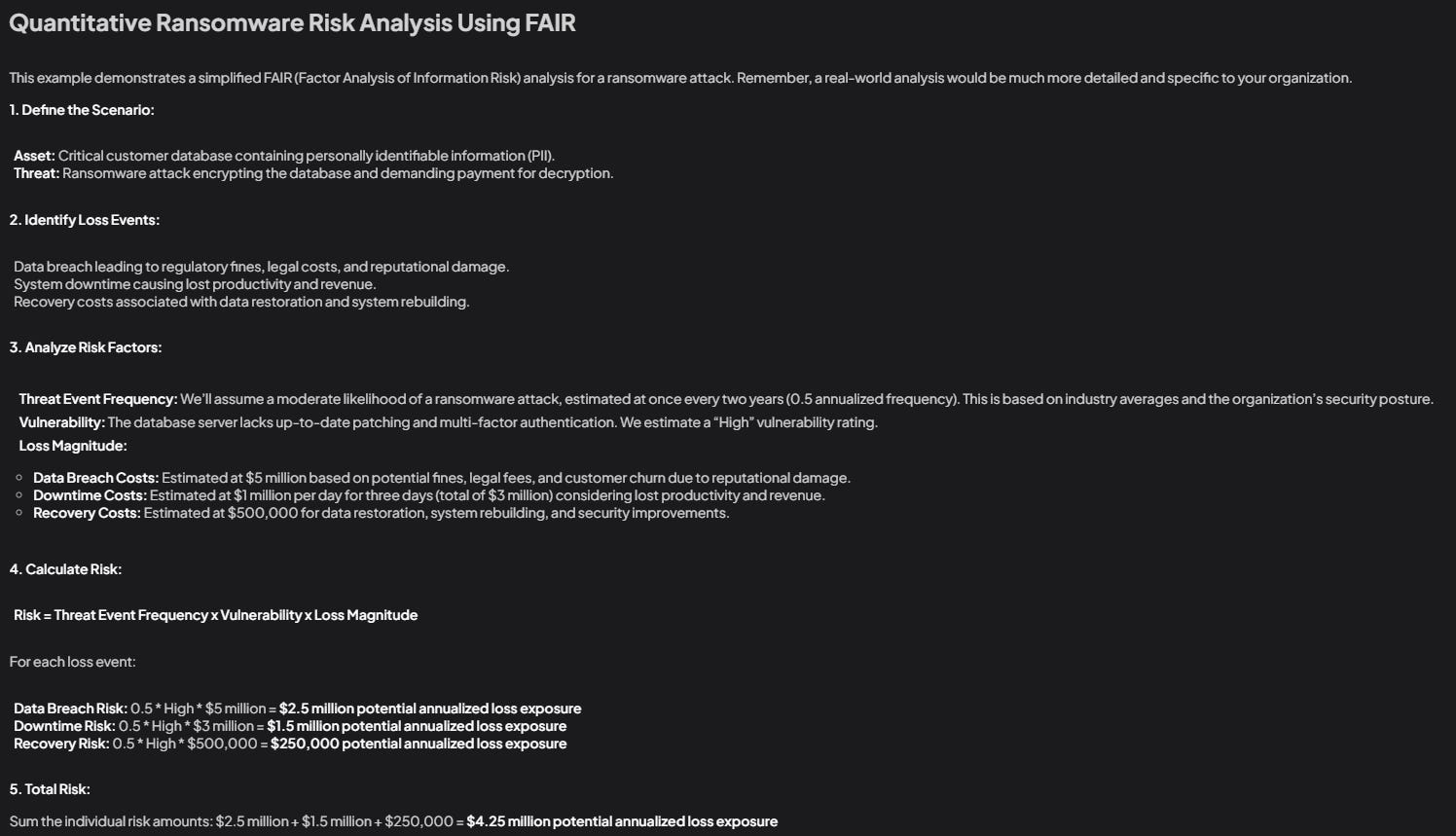
As expected, the more parameters a model has, the more detailed the answer gets. On the other side a high quantization does not necessarily bring in more precision. However, according to my observations, the proneness to hallucinations drops as soon as you use higher quantization. This observation particularly applies for the Qwen-2.5 14B model.
The Bottom Line
High-end models such as Qwen 2.5 (32B) and Gemma-2 (27B) excel in performing detailed and comprehensive FAIR risk analyses. Mid-tier options like Llama 3 (16B) and Qwen 2.5 (14B) offer a well-rounded combination of clarity and performance for general applications. Lower-parameter models, including Teuken and Mistral (7B), need further training to enhance their quantitative reasoning. Future research should focus on fine-tuning these models using specialized cybersecurity datasets to boost their domain-specific effectiveness.
In terms of precision it makes sense to utilize higher quantized models. But this will comes to the cost of limiting or even reducing the size (parameters) of the model in order to fit to your hardware environment.
If you seek overall a better performance for these use cases, it is recommended to use a larger model and use more parameters rather than using a model with high quantization.
It appears to me that the Teuken and Gemma models align closely to what is reported in daily data breach news. As usual, accurate asset values must be derived and input to the model. Otherwise it’s the usual GIGO report. Fascinating read!
Thank you and great observations, Paul.
Yep, accurate asset values might be THE bottleneck. Noatter how good your LLM is, if the (trained) data ist rubbish, your analysis will yield no meaningful results